Introduction to RAG
Go beyond generic AI responses. Learn to build accurate, source-grounded AI applications that leverage your own data. Master the foundational architecture powering the modern AI stack.
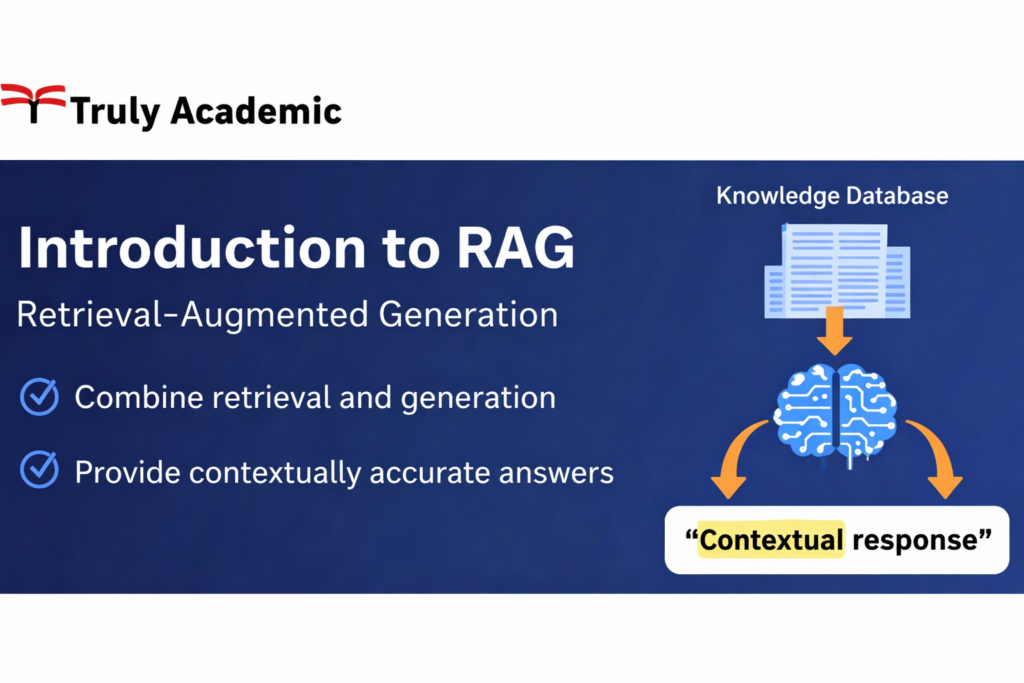
This practical course from TrulyAcademic demystifies Retrieval-Augmented Generation (RAG), the essential technique for making Large Language Models (LLMs) knowledgeable, trustworthy, and relevant to your specific domain. Designed for developers, data practitioners, and AI enthusiasts, you’ll move from theory to practice, learning to construct your own RAG pipeline from the ground up to combat LLM hallucinations and build AI solutions powered by proprietary documents, knowledge bases, and dynamic data.
Key Highlights of This Course:
Master the Core RAG Architecture: Gain a crystal-clear understanding of the end-to-end RAG pipeline—from document ingestion and processing to retrieval, augmentation, and final generation. Learn why RAG is critical for accuracy and cost-efficiency in enterprise AI.
Hands-On Ingestion & Chunking Strategies: Learn the art and science of preparing your data. Implement practical text splitting/chunking techniques using semantic and document-aware methods. Understand how chunk size and overlap directly impact retrieval quality.
Deep Dive into Embeddings & Vector Search: Demystify the magic behind vector databases. Learn to create text embeddings using leading models (OpenAI, Sentence Transformers), store them efficiently, and perform fast similarity search using platforms like Pinecone, ChromaDB, or Weaviate.
Build and Optimize the Retrieval Engine: Move beyond simple keyword matching. Implement and compare dense retrieval, learn about hybrid search (combining vectors with keywords/filters), and apply advanced techniques like re-ranking to fetch the most relevant context for the LLM.
Prompt Engineering for RAG: Specialize your prompts to effectively utilize retrieved contexts. Learn patterns for crafting system prompts and user queries that instruct the LLM to faithfully ground its answers in the provided sources and cite references.
Evaluation & Debugging Frameworks: Learn how to measure what matters. Move beyond intuition to implement both automated metrics (retrieval hit rate, context relevance) and LLM-as-a-judge evaluations to systematically assess and improve your RAG system’s performance.
Practical Project Portfolio: Apply your skills by building two key projects: a Document Q&A Assistant and a Technical Support Bot. Learn to handle real-world challenges like handling multiple file types (PDFs, PPTs, HTML) and managing conversational history.
Introduction to Advanced Patterns: Get a roadmap for the future by exploring next-level concepts like Query Expansion, Agentic RAG (where the AI decides to search), and Multi-Hop Retrieval, preparing you for more complex implementations.
Toolchain Proficiency: Gain hands-on experience with the industry’s favorite frameworks, including LangChain and LlamaIndex, to accelerate your development and understand the abstraction layers that make building RAG systems faster.
Best Practices for Production: Focus on foundational considerations for real-world deployment, including security, data privacy, pipeline monitoring, and cost management of embedding models and LLM API calls.